
Necesario conocer la inmunidad y los niveles de protección de la población, y tomar en cuenta la incertidumbre
Ciudad de México.- Los modelos matemáticos no tienen la verdad, sólo pueden proporcionar escenarios o posibilidades para predecir la pandemia de COVID-19, ya que se enfrentan diversas dificultades, señalaron expertos de la UNAM.
En el Foro 2020, Lecciones de la pandemia, organizado por Fundación UNAM, Gustavo Olaiz Fernández, coordinador general del Centro de Investigación en Políticas, Población y Salud de la Facultad de Medicina (FM), explicó que esta modelación tiene que ver no sólo con estimación de parámetros o datos, sino con condiciones de incertidumbre y complejidad.
Señaló que hay dos opciones básicas de política de salud pública para controlar una enfermedad infecciosa para la cual no hay vacunas ni tratamientos eficaces: aislamiento efectivo de los individuos sintomáticos, y el rastreo y cuarentena de sus contactos. Ambas están basadas en una rápida difusión de la información y sobre todo en un diagnóstico preciso.
Para predecir la pandemia, dijo el experto, se enfrentan diversas dificultades, y la primera es conocer la inmunidad y los niveles de protección de la población. “Se ha visto que existe la posibilidad de que otros coronavirus nos den algún tipo de inmunidad cruzada, la cual podría ser tan importante en un 20 por ciento; eso cambia radicalmente a la población susceptible y los modelos deben ajustarse a trabajar con el 80 y no con el 100 por ciento de la gente”.
En estos primeros meses, se ha visto que hay pocas probabilidades de que se registre una recaída de la enfermedad, es decir, estamos razonablemente protegidos después de haber sido infectados con COVID-19. Esperamos que eso ocurra; sin embargo, también dificulta determinar hacia dónde va la pandemia.
La proporción de personas sin o con pocos síntomas ha sufrido modificaciones porque cambia el conocimiento sobre ellos. La mejor estimación actual es que poco más de la mitad de la gente que se infecta no los va a tener; no obstante, esa proporción puede ir desde 25 a 75 por ciento. A eso se suman los “súper diseminadores”, gente que tiene una cantidad de virus “espeluznante” en sus vías respiratorias y los transmiten con mucha facilidad.
En la sesión “COVID-19 y su modelación matemática: ventajas y limitaciones” del Foro, Olaiz Fernández añadió que hay que evaluar la incertidumbre, presentarla y reconocer el error que tienen los modelos. “Éstos no han sido eficientes porque estamos modelando con base en casos, dependen de identificarse y de que se hagan suficientes pruebas, en cientos de miles, para reconocerlos”.
Jorge Velasco Hernández, integrante de la sede en Juriquilla del Instituto de Matemáticas, expuso que el concepto de número reproductivo es central en el estudio de ecología evolutiva, demografía y genética poblacional.
Se trata de las infecciones secundarias que un caso puede generar en una población susceptible durante el tiempo en que es infeccioso. “Mide el potencial de transmisión, pero es altamente variable porque depende no sólo del tipo de virus, sino de características poblacionales, regionales y geográficas, usos y costumbres”.
En el caso del SARS-CoV-2 los números reproductivos se han calculado entre 1.4 y 5.7, que es un rango amplio, pero no muy diferente de otras enfermedades infecciosas. No es de los virus más transmisibles, pero sí de los que han inducido mayor mortalidad en la población.
Para calcularlo, abundó, se necesitan varios conocimientos, entre ellos cuánto tiempo tarda la epidemia en duplicar el número de casos desde que inicia; o el periodo observado posterior a la introducción de las medidas de distanciamiento social.
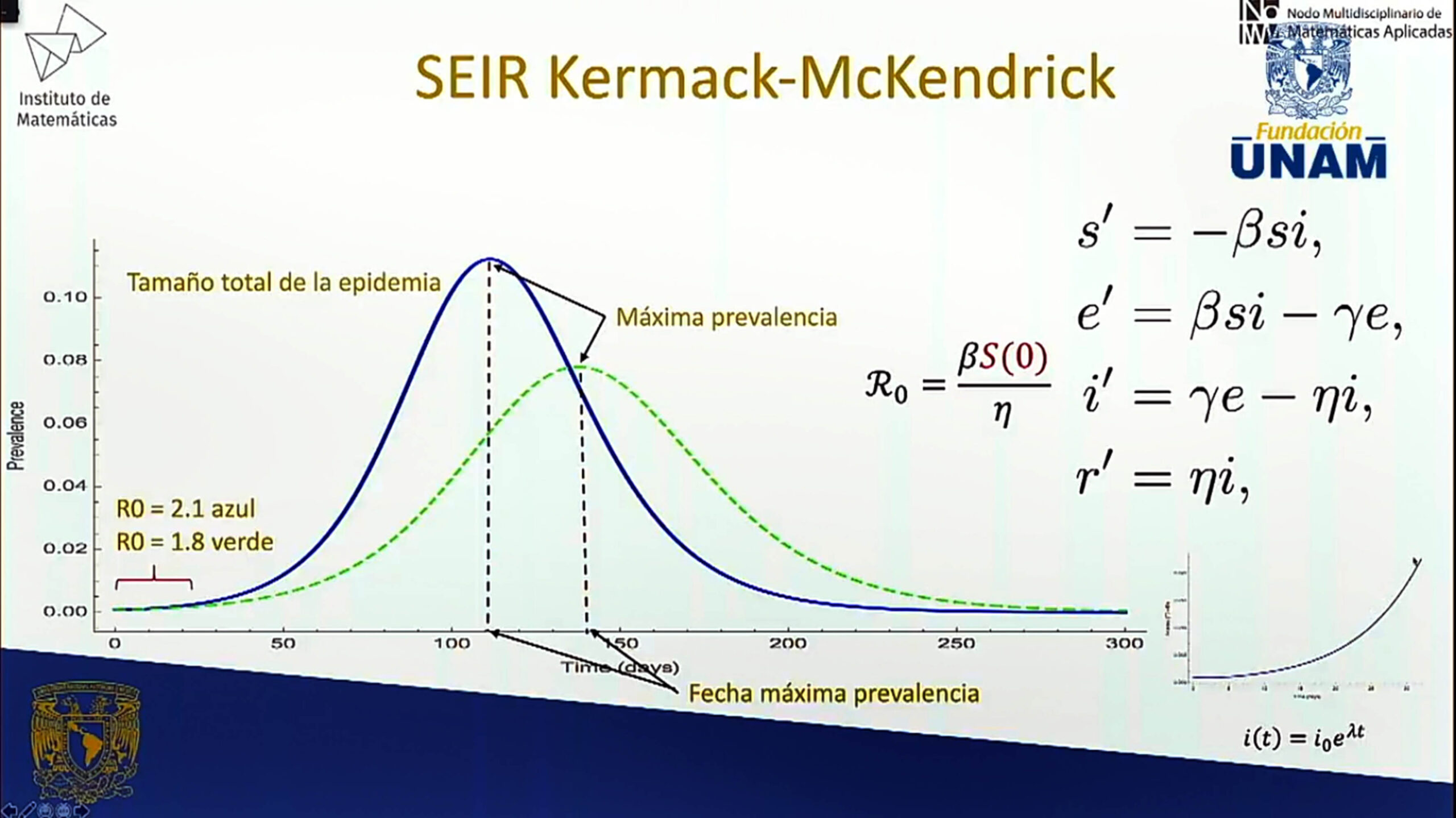
Ciertos modelos han tomado fama en los últimos meses, como el SEIR Kermack-McKendrik, que clasifica a la población en susceptibles, infecciosos y recuperados (que adquieren alguna inmunidad o han muerto).
No obstante, con el confinamiento hay una caída fundamental en el número de contactos, y existe un umbral debajo del cual las aproximaciones de ese modelo ya no pueden dar cuenta de la epidemia. Por eso es difícil describir su crecimiento.
También se presentan eventos de súper dispersión, situaciones o lugares (bares, fiestas, eventos familiares) donde el esparcimiento va mucho más arriba de lo que se puede esperar por el número reproductivo básico. En Hong Kong se encontró que la mayoría de las personas infectadas no contagiaron a alguien, pero otras pocas infectaron hasta a once más, refirió.
En la sesión en la que estuvo el presidente de Fundación UNAM, Dionisio Meade, Ramsés Humberto Mena Chávez, director del Instituto de Investigaciones en Matemáticas Aplicadas y en Sistemas, señaló que cuando pensamos en la incertidumbre de los fenómenos aleatorios, sabemos que controlan de alguna manera nuestra vida cotidiana. Así ocurre cuando hay eventos fortuitos como un terremoto o inundación.
La pregunta es cómo cuantificar la incertidumbre, aunque sea de manera parcial. “Es muy importante comunicarla, dejar claro que lo que vamos entendiendo tiene alcances y es sólo una proyección dada provisionalmente, con base en los datos de ese momento”, comentó.
La información ha servido para tomar decisiones importantes en torno a la pandemia, aunque surge la cuestión de si los modelos que se están usando son correctos. La dificultad de predecir una “curva” radica en que ello depende de múltiples factores externos, concluyó. (UNAM)



{kind=link}